Distributed Reinforcement Learning Algorithm for Multi-UAV Applications
The problem of learning a global map using local observations by multiple agents lies at the core of many control and robotic applications. Once this global map is available, autonomous agents can make optimal decisions accordingly. The decision-making rule is called a policy.
The development of policies is often very challenging in many applications as generating accurate models for these domains is difficult in the presence of complex interactions between the agents and the environment. For this reason, machine learning techniques have been often applied to policy development. Reinforcement Learning (RL) is a class of machine learning algorithms which addresses the problem of how a behaving agent can learn an optimal behavioral strategy (policy), while interacting with unknown environment. However, direct application of the current RL algorithms to the real-world tasks that involve multiple agents with heterogeneous observations may not work. Without information sharing between agents, the surrounding environment for each independent agent becomes non-stationary due to concurrently evolving and exploring companion agents.
We study a distributed RL algorithm for multi-agent UAV applications. In the distributed RL, each agent makes state observations through local processing. The agents are able to communicate over a sparse randomly changing communication network and can collaborate to learn the optimal global value function corresponding to the aggregated local rewards without centralized coordination. The overall diagram is shown in the figure below, where N agents and take actions locally, while communicating over the network.
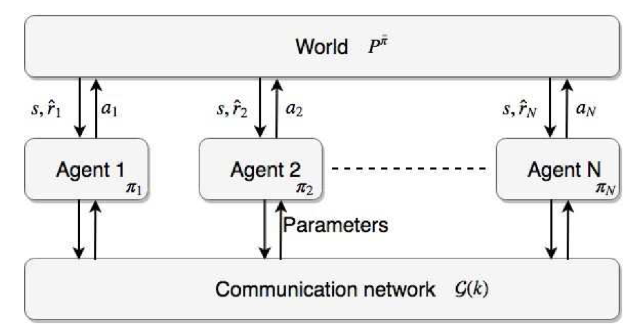
As an example, consider multiple heterogeneous UAVs equipped with different sensors that navigate a shared space to detect harmful events, for instance, frequent turbulence in commercial flight routes, regions frequently infested by harmful insects over corn fields, or enemies in battlefields. Using the distributed RL, these UAVs will be able to maneuver the space together to collect useful data for building a value function and designing a safe motion planning policy despite the incomplete sensing abilities and communications.
A simple example of the distributed RL is demonstrated in this animation:
[youtube]https://www.youtube.com/watch?v=CkHbUS65pLQ[/youtube]
Here three UAVs (agent 1 (blue), agent 2 (red), and agent 3 (black)) are equipped with different sensors that can detect different regions, while a pair of UAVs can exchange their parameters when the distance between them is less than or equal to 5. The blue region is detected only by agent 1 (blue circle), the red region is detected only by agent 2 (red circle), and the black region only by agent 3 (black circle). The results suggest that all agents successfully estimate the value function of the three regions.
Another example is illustrated in the following animation:
[youtube]https://www.youtube.com/watch?v=9p-Pi8w9S6U&t=18s[/youtube]
Here the goal is to find a value function that informs the three regions represented by black rectangles. In this example, all agents have identical sensors, while their routes cover different regions. However, the formation of three UAVs allows them to cover a broader space and detect the regions more efficiently. As a result, by sharing their information through a network, they can learn the value function that cannot be learned only by a single agent.